
 Proveniente de la mitología nórdica, Muninn era uno de los dos cuervos que proveía al Dios Odín con información diaria de lo sucedido en todo el mundo.
Proveniente de la mitología nórdica, Muninn era uno de los dos cuervos que proveía al Dios Odín con información diaria de lo sucedido en todo el mundo.
Sin duda, un nombre excelente para resumir lo que hace este magnífico proyecto. Munin es una aplicación con infraestructura cliente - servidor que recopila información de los nodos de una red y genera gráficas con las estadísticas.
Esto nos permite encontrar cuellos de botella en servidores, ver que ordenadores estan haciendo un uso más intensivo de la red, detectar y predecir fallos en el hardware (especialmente en discos duros), etc...
La arquitectura de este programa es bastante simple, por un lado en cada ordenador que queramos monitorizar debemos instalar el paquete munin-node y configurarlo para permitir conexiones desde el servidor central. En el servidor central hay que instalar el paquete munin, tiene que ser configurado indicando qué ordenadores tiene que monitorizar y donde debe generar las gráficas.
Para instalar los paquetes:
apt-get install munin munin-node munin-plugins-extra apache2
Existe un port para Windows del paquete munin-node, pero no ofrece tanta información útil como las versiones para Linux.
Para configurar el paquete munin-node:
Editamos el archivo /etc/munin/munin-node.conf añadiendo la IP del servidor central como permitida, en este ejemplo el servidor tendrá la IP 192.168.0.1:
allow ^192\.168\.0\.1$
En este mismo archivo podemos cambiar en que interfaz de red debe escuchar el programa y que puerto utilizar (por defecto 4949), no es necesario modificarlos pero sí tenerlo en cuenta si es necesario configurar el firewall.
Para configurar el paquete munin:
Editamos el archivo /etc/munin/munin.conf añadiendo los ordenadores que debe explorar cada 5 minutos:
[pcubuntu]
address 192.168.0.2
use_node_name yes
[pcwindows]
address 192.168.0.3
use_node_name yes
Y en el archivo /etc/munin/apache2.conf modificaremos la configuración para acceder a los gráficos generados, en principio sólo es recomendable cambiar el primer Alias, aunque también podríais ponerle contraseña HTTP si quereis restringir el acceso.:
Alias /monitor /var/cache/munin/www
Por defecto el número de gráficos que genera munin es cuantioso, y más si se instalan plugins adicionales o los creais vosotros mismos. No es dificil, permite crear los plugins como un script shell cualquiera (incluído PHP, python ó PERL) lo que nos permite monitorizar cualquier cosa, como por ejemplo un termómetro USB. En este caso no me voy a detener mucho explicando esta funcionalidad. Si quereis investigarlo, los plugins se pueden encontrar en /etc/munin/plugins donde la mayoría son enlaces blandos hacia /usr/share/munin/plugins.
Tras configurar todo y darle algo de tiempo para que genere datos (monitoriza cada 5 minutos, así que habría que esperar una hora aproximadamente para tener algo que analizar), podremos acceder a los gráficos generados bajo la ruta (continuando con la IP del servidor anterior):
Estos gráficos se generan gracias a la librería RRDtool, que da muy buenos resultados.
Podemos ver una lista de los equipos monitorizados, pinchando en cada uno accederemos a un listado de gráficos detallados. Os pongo aquí como ejemplo algunos datos recogidos en mi servidor y algunos comentarios sobre los mismos:
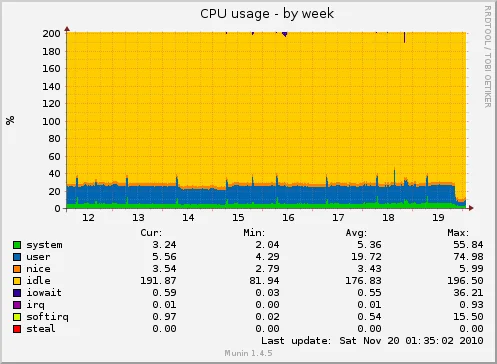
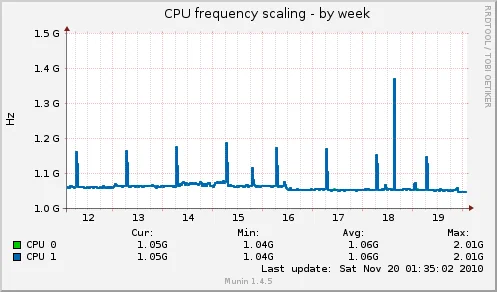
Escalado de la CPU, el procesador no está funcionando siempre al tope de rendimiento, este gráfico muestra la frecuencia media a la que suele funcionar y en qué momentos el servidor tuvo que aumentar la frecuencia para atender una tarea (en mi caso coincide con la rotación de logs de madrugada):
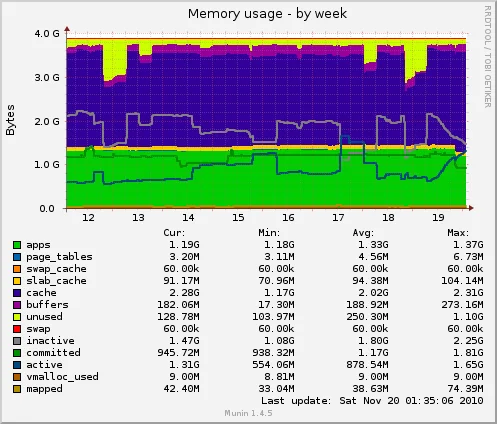
Uso de memoria semanal:
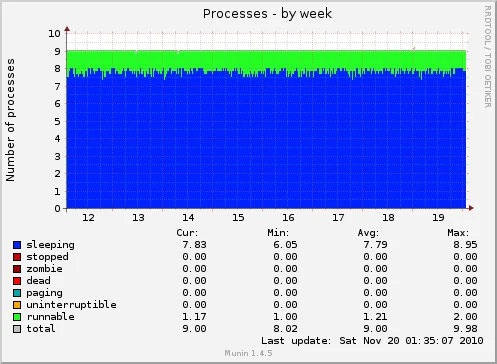
Número de procesos ejecutados a lo largo de la semana (bastante estable la verdad :)):
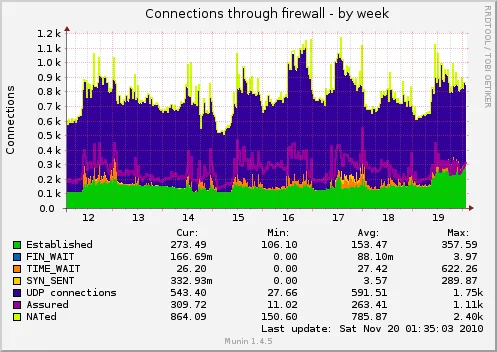
Número de conexiones simultáneas que pasan por el servidor, en mi caso actúa como enrutador de toda la red (el router está en modo bridge) y como podeis ver mantener más de 2.500 conexiones simultáneas es demasiado para un router convencional. En otros gráficos posteriores he llegado a ver picos de 4.500 conexiones simultáneas:
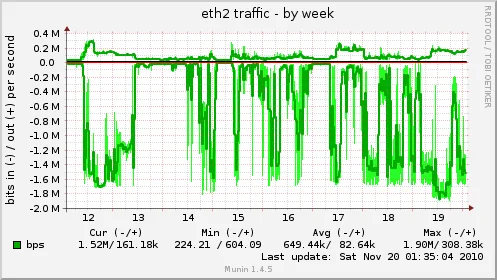
Estadísticas de la interfaz eth2 (la que tiene la IP externa de internet), en positivo la velocidad de subida, en negativo la velocidad de descarga (ahí esos 2 Mbits bien exprimidos xD):
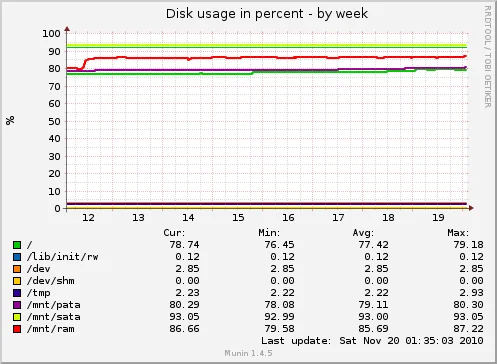
Estadísticas de espacio ocupado en los puntos de montaje del servidor:
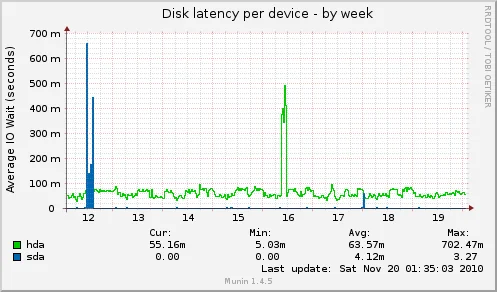
Estadísticas de la latencia de los discos duros (tiempo que han tardado a una petición de lectura o escritura), si aumentan mucho puede ser señal de fallos de hardware:
Hay muchos otros gráficos interesantes como el uso de SWAP, estadísticas de Samba, Squid, información S.M.A.R.T. de los discos duros, etc...
Si utilizamos este programa en un servidor de producción, podremos detectar si en algún momento el número de peticiones HTTP hace que el servidor se quede sin memoria libre y empiece a utilizar la SWAP, además, si alguno de los gráficos da valores de riesgo, munin resalta esos gráficos para que fijemos la atención en ellos. También podemos diagnosticar cuellos de botella en la red si no da abasto el procesador en operaciones de copia por red o con los discos duros, etc...
En mi caso hacía mucho tiempo que buscaba una aplicación como esta y supe de su existencia gracias a un post de barrapunto. Espero que este post sirva como referencia para quien busque una aplicación de monitorización bastante completa.
Si alguien tiene algún problema o duda en el proceso de instalación o configuración podeis plantearlo en los comentarios, os ayudaré en lo que pueda.
Un saludo. 🙂